
深入浅出XGBoost:从原理到应用的全面指南

DMSAS
2024-12-13 00:00:00
假设你是某电商平台的数据分析师,业务目标是提升用户购买率,现在你们团队希望预测:哪些用户更可能购买某种商品?
一开始,大家可能尝试简单的逻辑回归,结果发现模型预测准确率只有70%。为什么?因为用户行为复杂,逻辑回归的假设太过简单,难以捕捉复杂的非线性关系。后来,你换用随机森林,准确率提升到了80%,但计算时间太长......
这时候,XGBoost登场了!
它不仅能处理复杂的特征关系,准确率高,还能通过特征重要性等手段帮你解释结果,同时优化了计算效率。这种强大的平衡能力,使得XGBoost在电商、金融、医疗等行业广泛应用。
01什么是XGBoost?
XGBoost(eXtreme Gradient Boosting)是一种基于决策树的分布式梯度提升(GBDT)框架,被广泛用于各种机器学习任务,尤其是在数据量较大、特征复杂的场景下表现尤为优异。
XGBoost基于传统的梯度提升算法有了以下几点优化:
- 正则化:引入L1和L2正则化,减少过拟合风险。
- 并行计算:利用并行化技术加速树的构建。
简单来说,XGBoost是一种基于决策树的集成算法。
它的基本想法是把简单的模型(弱学习器)组合成一个强大的模型,通过一次次纠正预测误差,不断提升模型的预测能力。
举个例子:
• 第1棵树预测结果A,但有些数据预测错了,生成了“残差”(即误差)。
• 第2棵树专门来学习和修正这些残差。
• 第3棵树继续修正之前的错误,直到整体误差被压缩到一个非常低的水平。
最终的预测结果是所有树预测结果的加权和。(像是一种“众人拾柴火焰高”的算法)
02XGBoost的核心原理
XGBoost的本质是逐步优化误差,通过一轮轮的迭代,使模型逼近真实值。
可以把XGBoost想象成一个优秀的老师,带着一群学生(决策树)一起学习。学生们一开始水平参差不齐,但老师发现问题后,会帮助每个学生专门练习薄弱点,经过几轮训练,大家的总体水平越来越高。最终,每个学生的长处被充分利用,整体团队拿到了优异的成绩。
2.1 XGBoost的核心算法流程:
- 初始化模型:假设初始预测值为常数(如均值)。
- 计算残差:基于目标函数的负梯度估计误差。
- 生成决策树:拟合当前的残差,生成一棵新的决策树。
- 更新模型:将新树的预测结果与前几轮的预测值加权求和。
- 多轮迭代:不断重复,最终收敛于最优解。
2.2 XGBoost算法中的几个重要概念:
a. 目标函数(Objective Function)
目标函数包括两部分:
- 损失函数:衡量预测值与真实值之间的差距,比如均方误差(MSE)或对数损失(logloss)。
- 正则化项:控制模型复杂度,防止过拟合,比如限制树的深度或叶节点的数量。
目标函数的数学表达:
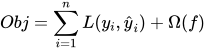
其中,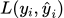 是损失函数,用来衡量模型的预测误差;
是损失函数,用来衡量模型的预测误差;
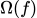 是正则化项,用来限制模型的复杂度。
是正则化项,用来限制模型的复杂度。
b. 梯度提升(Gradient Boosting)
每一轮迭代中,XGBoost根据损失函数的梯度来调整模型参数。可以理解为:梯度告诉我们“错误的方向和大小”,模型用这些信息逐步纠正自己,直到错误越来越小。
c. 树的构建
- 分裂节点:XGBoost通过贪心算法(Greedy Algorithm)找到每个分裂点的最佳位置,从而最大化信息增益。
- 叶节点优化:使用二阶导数信息来计算叶节点的权重,提升收敛速度和预测精度。
d. 特殊优化
- 并行化:XGBoost在寻找分裂点时采用并行计算,对于大规模数据集可以大幅缩短训练时间。
03基于DMSAS实现XGBoost
我们来看一个经典的业务案例:企业是否破产?
希望通过调查企业的经营状况识别企业是否会破产,确保精准率和召回率达到合理平衡。
挑战:
1、破产企业比例只有3.9%,类别不均衡;
2、调查的特征数量为64个,特征过多,需要实现降维。
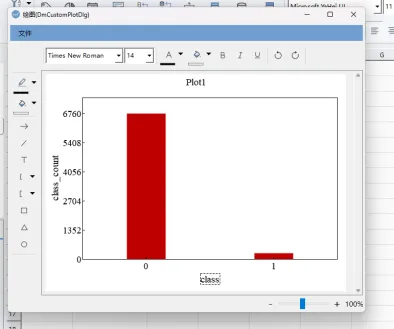
解决方案:
数据预处理:
1、首先使用PCA功能,查看64个特征是否能进行一定程度的缩放;
2、对少数类别进行过采样(SMOTE),增强模型对破产类判别的敏感性。
下面,我们就以DMSAS的实现为例,讲解使用XGBoost建模全部流程:
Step1: 通过主成分分析观察特征向量可以被压缩的维度:
操作步骤:分析→主成分...→主成分分析
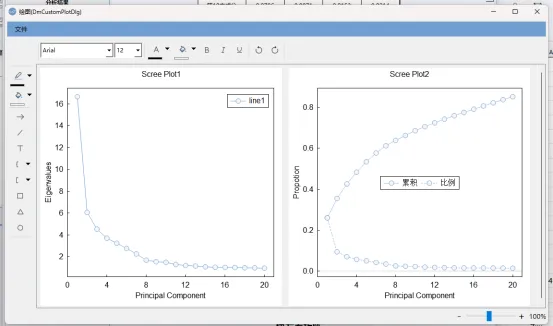
从主成分分析的结果可以看出,64个特征被降维至12个时,特征分解的曲线逐渐趋于平稳,前12个特征可以解释总体变异程度的75%,表明可以将64个特征降维至12个特征做机器学习建模。
Step2: 构建机器学习模型:
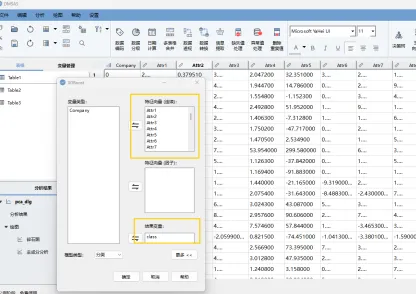
2.1 打开XGBoost窗口
操作步骤:分析→机器学习→XGBoost,将64个特征向量全部放入“特征向量(连续)”选项框,将企业破产变量(class)放入“结果变量”选项框。
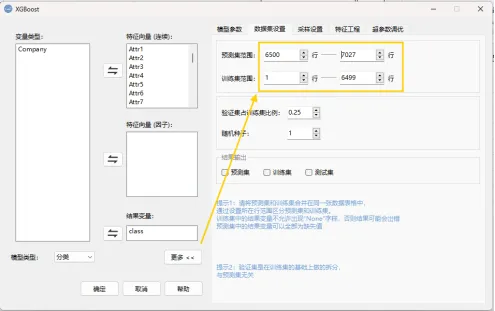
2.2 拆分预测集与训练集
点击“更多”→“数据集设置”,将预测集范围设置为6500-7027行,将训练集范围设置为1-6499行。
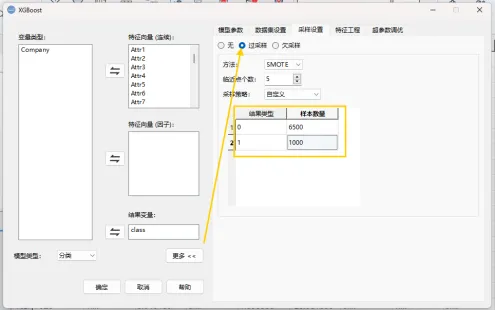
2.3 设置Smote过采样
点击“更多”→“采样设置”→“过采样”,在采样策略中定义过采样规则。
2.4. 调整模型参数:
- 学习率(learning_rate):控制每棵树对最终模型的影响,通常默认0.1。
- 最大深度(max_depth):控制单棵树的复杂度,推荐范围3-10。
- 平行学习器个数(n_estimators):决定迭代次数,过多可能导致过拟合。
操作步骤:点击“更多”→ “模型参数”
2.5 对64个特征做降维
操作步骤:点击“更多”→ 特征工程,勾选“降维”后,在下方的“方法”中选择“主成分”,降维特征维度设置为12。
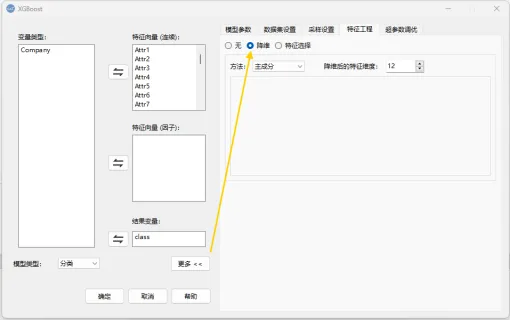
2.6 点击“确定”运行模型即可。
04 XGBoost的模型结果解读
现在,我们结合实际业务场景来理解XGBoost的结果评估。
几种常见算法模型评估指标:
- 准确率(Accuracy):预测正确的样本占总样本的比例。适合正负样本均衡的数据集,但对于严重失衡的数据(如欺诈检测)可能不够灵敏。
- 精准率(Precision):预测为正样本中实际为正样本的比例。精准率适用于当误报(假阳性)所造成的后果比较严重的场景,比如医疗诊断中的癌症筛查。
- 召回率(Recall):实际正样本中被正确预测为正样本的比例。当漏报(假阴性)所造成的后果代价更高时,比如信用卡欺诈检测。
- F1-score:精准率和召回率的调和平均值。
当需要同时平衡精准率和召回率时使用。
如果精准率高但召回率低,说明模型预测更“保守”,可能漏报部分欺诈交易,需要优化特征或调整权重。
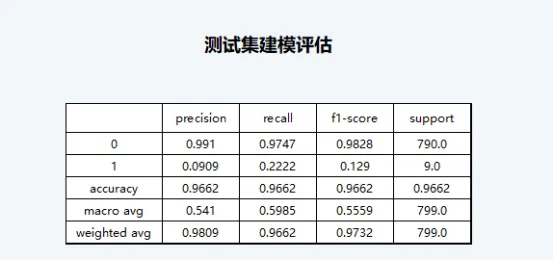
从当前模型的运行结果来看,尽管模型的准确率达到了96.62%(accuracy),但模型对结果变量为1(公司破产)预测的召回率仅为22.22%,精准率仅为9.09%,表明在预测公司破产这件事情上的效果不佳,但对公司不会破产这件事的预测效果较好。
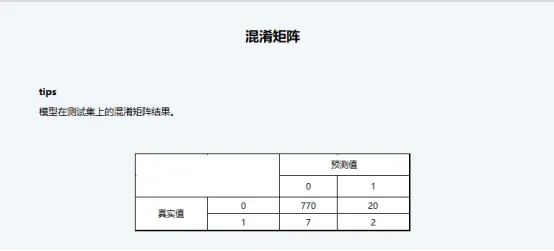
混淆矩阵:清晰展示分类任务的正确预测和错误预测情况。
从混淆矩阵的展示结果来看,真实值为1并且最终被预测为1的案例仅有2例,有7例被预测为了0,表明模型的确对1(企业破产)的预测状况不佳。
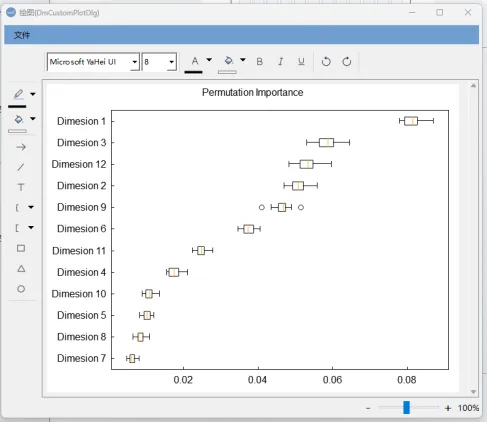
特征重要性分析:揭示哪些特征对模型的影响最大。
通过置换特征检验可以看到,主成分中成分1、成分3和成分12对建模起到的贡献作用较大。
分析结果讨论
通过本次建模结果可以看出,虽然模型的准确率达到了97%,但模型本身对企业破产(结果变量为1)这件事情的发生预测并不准确。因此若应用这一模型时很可能会产生一个问题:由于企业破产在调查数据中的占比本来就较少,那么这一模型只需要将所有企业都预测为不会破产,它的建模准确率就能够达到一个相当高的水平,但这一模型在实际应用中的价值并不大,因为我们可能更想关注的是企业破产这一事件。因此这一机器学习模型要想得到很好的应用,还应进行更多的参数调整工作(对超参数的调整,可以尝试使用机器学习功能,“更多”中的“超参数调优”板块)。